
2026.04.27

こんにちは。NANAシステム開発SYです。今回は技術ネタです。
SQL Server を運用していると、tempdb のサイズが気づいたらとんでもなく大きくなっていた――という経験は多くの管理者が一度は通る道ではないでしょうか。
先日、まさに自分の環境で同じ状況に遭遇し、「これはさすがに大きすぎるのでは?」と思って調査を始めました。
ところが色々調べていくうちに、
「あれ?これ Microsoft の推奨サイズ(=適正サイズ)に近いのでは…?」
という結論に近づいていきました。
今回はその気づきと、実際に tempdb がどれだけ使われているかを記録し、最適サイズを導き出すまでのプロセスをまとめます。
tempdb は SQL Server の作業領域として、次のような処理に使われるようです。
・ORDER BY / GROUP BY など大規模ソート
・ハッシュ結合・ハッシュ集計
・一時テーブル・テーブル変数
・Snapshot Isolation / RCSI のバージョンストア
・インデックス再構築(ONLINE)
このため、上記をガンガン行うアプリケーションほど tempdb はよく伸びます。
しかも、SQL Server はサービス再起動のたびに tempdb を初期サイズにリセットするため、
初期サイズが小さいとピーク負荷時に一気に巨大化してしまうことがあります。
なので、「ファイルを小さくしても、また必要に応じて大きくなった」と感じることがあります。
tempdb の適正サイズは
「CPU コア数 ×(8GB 〜 16GB / ファイル)」
というのが Microsoft の基本推奨です。
例えば CPU 8コアなら:
・ファイル数:8個
・1ファイル初期サイズ:8GB
・合計:64GB
巨大化したと悩んでいた環境でふと確認すると、まさに この推奨レンジに収まっていた のです。
「巨大化した!」と焦ったわりには、ただの最適化された姿だったわけです。
でも、いくら推奨値に収まっているとはいえ、本当に適正かどうかはワークロードを見て決めるべきです。
そこで、tempdb の使用量を 時系列でログに残す仕組み を作りました。
以下のようにログテーブルを作り、
SQL Server Agent で 1分ごとに実行することで
ピーク時の tempdb 消費量を詳細に把握できます。
最初の数日記録をとってみて分かったのは、
・殆ど使っていない時間帯が多い
・逆に特定時間帯だけドカンと増える
ということ。
今後はログデータをもとに、
・ピーク使用量 + 20〜30% の余裕
・拡張が発生しない初期サイズ
・適切な autogrowth 設定(%ではなく固定MB)
これらを調整し、tempdb を“業務に最適化されたサイズ”へ整えていく予定です。
・TEMPDB は負荷によって大きくなるのが普通
・縮小してもまた必要に応じて拡張する
・Microsoft 推奨サイズに近いことも多い
・本当に妥当かどうかは、実際の使用量をログに残して判断するべき
・ログを取るとワークロードの癖が見えてくる
・そこから初めて “最適サイズ” の議論ができる
tempdb の巨大化は “壊れている” のではなく、「あなたのワークロードを反映した姿」 であることが多いです。なので大事なのは、まずは実測から始めることだと感じました。
これが tempdb 最適化のスタート地点だと実感した出来事でした。些細な情報ですが、皆様のお役に立てれば幸いです。

皆様、こんにちは♪ NANAシステム開発HYです。
今回は(も?)ちいかわグッズのお話です。
先日、KSさんから、
またまたUFOキャッチャーちいかわグッズが届きました♪
なんと、うさぎのUSBスタンドライトです!
目が光るとの事♪
さっそくパソコンへ繋いで… と思ったのですが、
弊社では許可されたもの以外のUSB接続は禁止。(^^;
という事で、とりあえず組立だけしました。笑。
KSさん、ありがとうございますっ!



皆様、こんにちは♪ NANAシステム開発HYです。
今回は、ハンバーグを食べに行ったお話です。
先日、昼休みにZAZA中央館の近くを散歩していたら、気になるお店を発見!
ひとりではちょっと寂しかったので、お客様を誘って、一緒に行ってきました。
「ハンバーグランチ Cafe de 一休」さんです。
https://hamamatsu-machinaka.jp/news/50353/
美味しかったです!
私は和風ハンバーグを注文したのですが、大根おろしがてんこ盛りで、とっても美味しかったです。
また行こうっと♪
こんにちは。NANAシステム開発SYです。たまに技術的なことも書いていこうと思います。
今回は Unity でビルドをしたときに遭遇した、「Windowsログインユーザー名が日本語だとビルドがこける」という問題について書いてみます。Unityが外国製なので、仕方ないと言えばそうなんですが、解消しないといけないですからね。
検索して出てくる解決策は、ほとんど以下の内容でした。
「1バイト文字のユーザー名で Windows ユーザーを作り直す」
でも、ユーザー作り直しってそんな簡単にやりたいもんじゃないですよね。
ということで、今回は 「何が起きているのか?」を正しく理解して対処する という方針で進めました。
■ まずはエラーログから読み解く
Unity のビルド時に表示されたエラーメッセージはこちら。
[CXX1429] error when building with cmake …
C++ build system [prefab] failed while executing
さらに詳細ログを見ていくと以下のようなことが書いています。
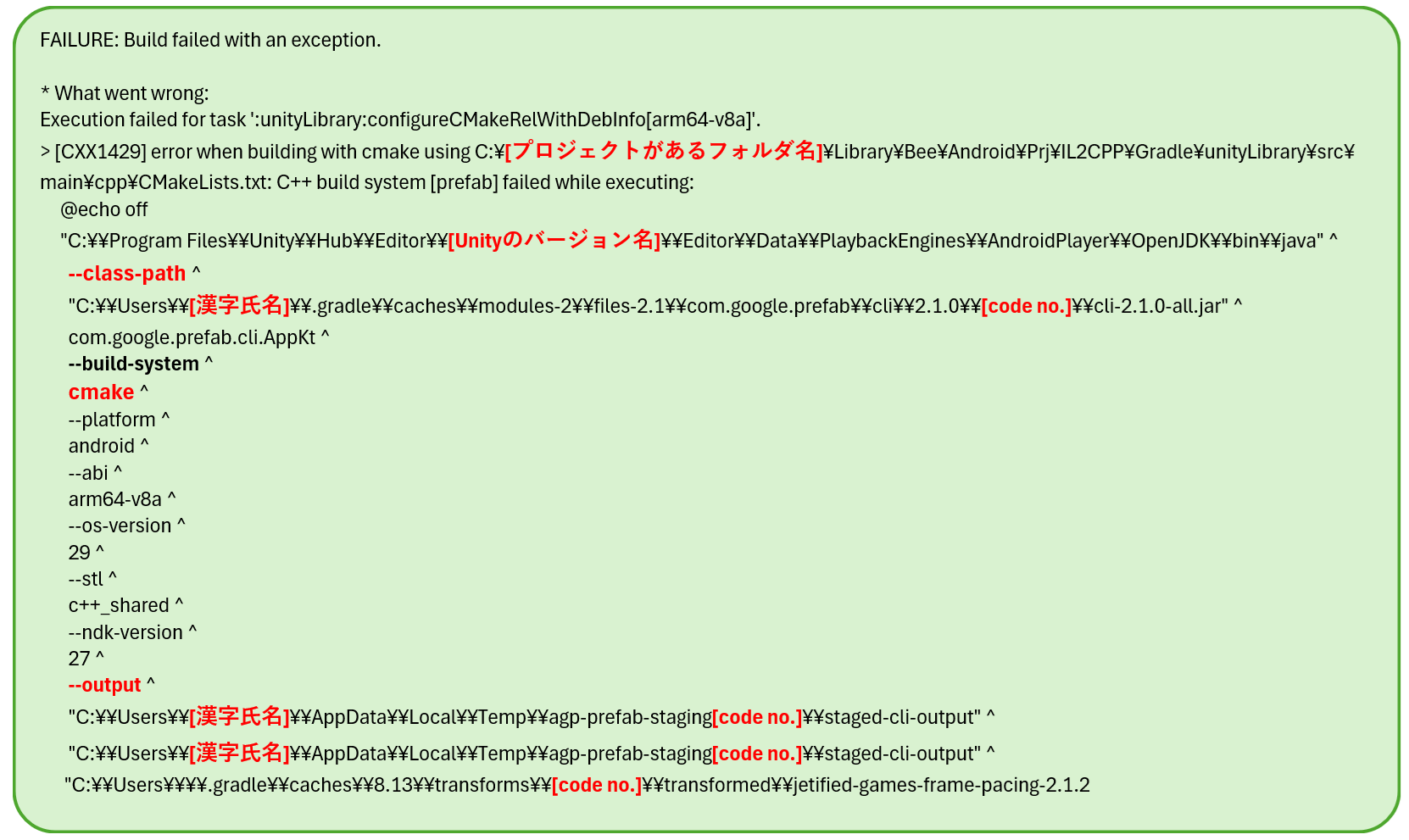
つまり、cmake が 2 バイト文字(日本語)を含むパスを処理できずに落ちているわけです。
Unity は表向きは日本語表記に対応しているのですが、
内部のビルド処理ではまだまだ 1 バイト文字前提の部分が残っています。
これが原因で、.gradle や Temp が参照されるタイミングでエラーになります。
ポイントは次の2つ。
1. cmake が参照する “ユーザーホーム” を 1 バイト文字のパスに置き換える
2. Unity や Windows が一時利用するフォルダ(Temp)も同様に変更する
では順番に設定していきます。
Unity の External Tools と GI Cache の設定を変更します。
▼ External Tools の設定
Edit → Preferences → External Tools
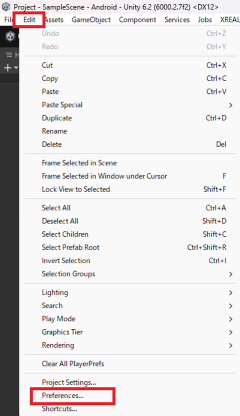
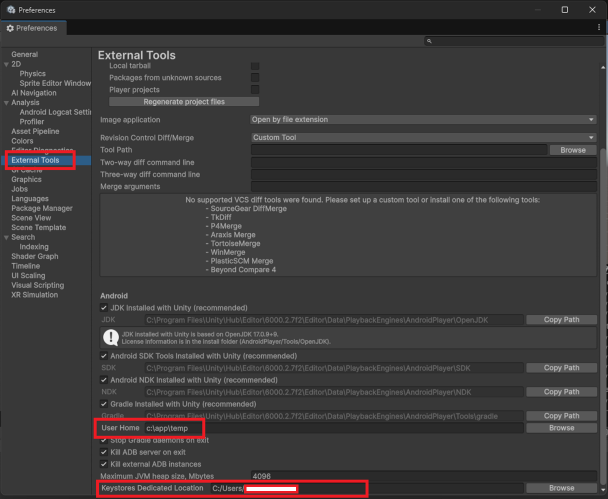
ここで以下を設定します
空欄になっている場合、1 バイト文字だけで構成されたフォルダ を指定します。
例)C:\UnityUserHome など
※ フォルダは先に作っておく必要あり
こちらも同じく 1 バイト文字パス を指定します。
▼ GI Cache の設定
Preferences → GI Cache
1.「Custom cache location」 にチェック
2. Browse から 1 バイト文字のパスを選択
3. Clean Cache を押してキャッシュをクリア
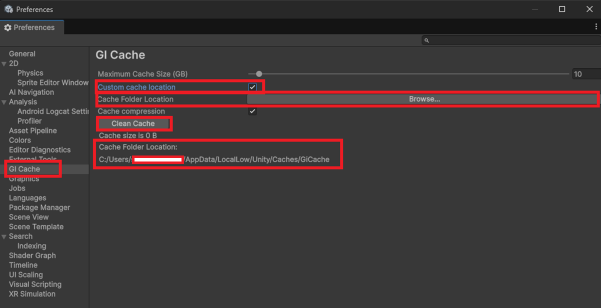
これで、Unity が内部で参照するキャッシュフォルダが安全なパスへ切り替わります。
cmake が参照する –output パスは Windows の TEMP/TMP に紐づくため、ここも 1 バイト文字パスに変更します。
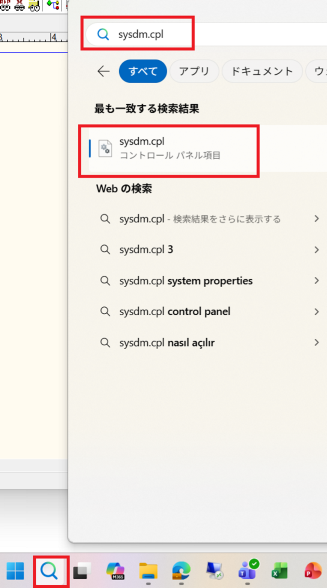
▼ 環境変数を変更する手順
1.タスクバーの虫眼鏡アイコンから「sysdm.cpl」を検索して開く
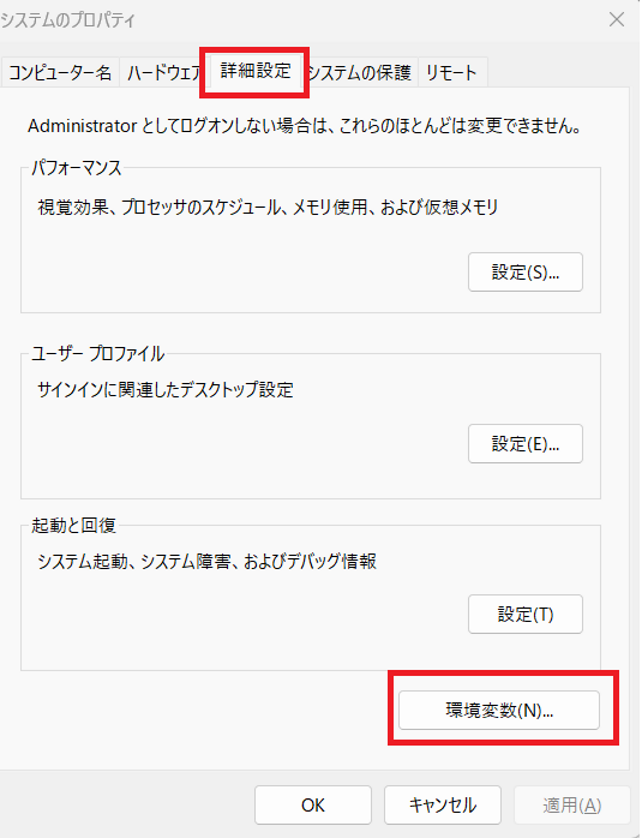
2. 詳細設定 → 環境変数 をクリック
3. ユーザー環境変数の TEMP と TMP を編集し、1 バイト文字だけのパス に変更する
例) C:\Temp
C:\WorkTmp
※ ここも事前にフォルダを作っておく必要があります。
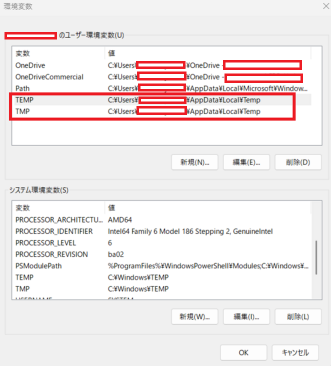
環境変数の変更は OS 再起動が必須です。
再起動後に Unity を開いてビルドすると…
無事にビルドが通りました!🎉
今回の問題は、
・cmake が 2 バイト文字(日本語ユーザー名)を含むパスを処理できない
・Unity/Gradle の内部処理が ユーザープロファイル配下を参照する仕様
という2つが重なったことで発生していました。
「ユーザーを作り直す」という力技ではなく、Unity と OS の参照パスを1バイト文字に逃がすことで解決できます。同じ問題にハマった方の助けになればうれしいです!

